[ 3. C언어의 기본 - 변수 & 자료형 ]
정보처리산업기사 실기 자격증 취득을 위해 알고리즘 공부를 시작!
기초부터 시작합니다.
키보드로 두 수를 입력받아 두 수의 덧셈 결과를 출력하는 프로그램을 작성
(코드는 귀엽게 봐주세요..)
|
#include <stdio.h>
int main() {
int a, b; // 입력받을 변수
char op; // 연산자
scanf("%d %c %d", &a, &op, &b);
printf("%d %c %d = %d", a, op, b, a + b);
}
|
cs |
순서도

① C언어에서의 변수란?
- 변수란 컴퓨터가 명령을 처리하는 도중 발생하는 값을 저장하기 위한 공간으로 변할 수 있는 값을 의미한다.
- 변수는 저장하는 값에 따라 정수형, 실수형, 문자형, 포인터형 등으로 구분된다.
- 즉, 데이터를 저장할 수 있는 메모리 공간이라고 생각하면 된다. 저장된 값은 변경될 수 있다.
예제로 한번 살펴보자.
|
#include <stdio.h>
main()
{
int A;
A = 3;
A = 120 + 10;
A = 30 + 30;
printf("%d\n", A);
}
|
cs |
변수에 저장되는 값은 무엇일까???
1) 정수형 A 변수를 선언
2) A에 3이라는 값을 넣어줌
3) 120+10 = 130이라는 값과 3을 더한다?
4) 30+30 = 60이라는 값과 133을 더한다?
5) 정답은 193 일까?
위에서 변수를 설명할 때, 변할 수 있는 값을 의미한다고 했다.
그러므로 결과는 마지막 줄 30+30 = 60 이다.
하지만, 193이란 숫자를 출력할 수도 있다.
|
#include <stdio.h>
main()
{
int A;
A = 3;
A = A + 120 + 10;
A = A + 30 + 30;
printf("%d\n", A);
}
|
cs |
연산에 A 변수를 호출하면 답은 193이란 결과를 얻었다. (한심하게 보시는 분들도 계실수도..ㅠㅠ)
※ 변수명(식별자) 규칙은 이러하다.
1) 대 / 소문자를 구분한다. // int dash , int Dash
2) 중간에 공백을 포함할 수 없다.
3) 첫 자는 영문자나 _로 시작해야 한다. - 숫자 시작 X // int 7seven X, int seven7 O
4) 예약어(Keyword)는 사용할 수 없다. // for, goto, else, default, case, break, continue 등등 많습니다.
5) 변수 선언 시에도 문장 끝에 반드시 세미콜론(;)을 붙여야 한다.
② 자료형(Type) 이란?
컴퓨터는 데이터를 인식하지 못한다. 0하고 1밖에 모르는 친구이기 때문에
사람이 이해하는 언어를 컴퓨터가 인식할 수 있도록 번역 및 통역해주는 것이 "컴파일"이라고 한다.
왜 컴파일 이야기가 나오는가하면 우리가 프로그램을 작성할 때 엉망으로 프로그래밍을 하면 당연히
컴파일에 오류가 나고, 컴퓨터는 코드를 알아볼 수 없게 될 것이다.
그래서 코드를 작성할 때 규칙을 정했는데, 바로 그 규칙이 바로 자료형이라고 한다.
변수가 저장할 데이터가 정수인지, 문자인지, 실수인지 미리 지정해주는 것이라고 이해하도록 하자.
프로그램에 있어서 자료형의 선택은 여러가지로 중요하다.
어떠한 자료형을 선택하느냐에 따라 계산값과 표현방법이 달라지는데,
여러가지의 자료형이 있는 이유는 결과도 있지만 메모리의 효율적으로 사용하기 위함도 있다.
한 개의 데이터는 큰 차이가 없긴하지만, 수 많은 데이터를 1바이트씩만이라도 줄인다면 그 크기는 엄청나다.
예를들어 천원씩 저금한다고 하자. 이것이 지금은 천원이지만, 5년 후에는 무시못할 금액이 될 수 있다.
즉, 효율적으로 데이터를 관리하는 것과 대충대충 관리 하는것은 나중에 그 데이터 크기를 보면 엄청난 차이가난다.
또 압축파일로 예를 들 수 있다.
리눅스 OS 파일을 압축파일로 다운받았다. 압축파일 자체는 크진 않았는데
압축파일을 다운받고 압축을 풀어보면 기존에 받았던 데이터보다 더 많은 데이터가 들어있었다.
효율적인 저장 방식이 얼마나 차이가 큰지를 잘 보여주는 예시라고 할 수 있다.
자료형의 종류를 살펴보자.
| 구분 | 크기(Byte) | 범위 | ||
| 정수형 | char | 1 | -128 ~ 127 | |
| short | 2 | -32768 ~ 32767 | ||
| int | 4 | -2,147,483,648 ~ 2,147,483,647 | ||
| long | 4 | -2,147,483,648 ~ 2,147,483,647 | ||
| long long | 8 | -9,223,372,036,854,775,808 ~ 부호 없이 같음 | ||
| 실수형 | float | 4 | 밑에 결과 참고* | |
| dobule | 8 | 밑에 결과 참고* | ||
| long dobule | 12 | 밑에 결과 참고* | ||
자료형 범위를 찾아보면 범위값이 다 다르네요ㅋㅋㅋ 특히 실수형에서..
우리가 프로그램 작성해서 사용 범위를 한번 알아보도록 해볼까요?
|
#include <stdio.h>
#include <limits.h> // 정수형 데이터 타입의 최솟값과 최댓값을 알려주는 헤더
#include <float.h> // 실수형 데이터 타입의 최솟값과 최댓값을 알려주는 헤더
int main(void) {
// 정수형
printf("char : %d ~ %d", CHAR_MIN, CHAR_MAX);
printf("\n");
printf("short : %d ~ %d", SHRT_MIN, SHRT_MAX);
printf("\n");
printf("int : %d ~ %d", INT_MIN, INT_MAX);
printf("\n");
printf("long : %ld ~ %ld", LONG_MIN, LONG_MAX);
printf("\n");
printf("long long : %lld ~ %lld", LLONG_MIN, LLONG_MAX);
printf("\n");
//실수형
printf("float : %e ~ %e", FLT_MIN, FLT_MAX);
printf("\n");
printf("double : %e ~ %e", DBL_MIN, DBL_MAX);
printf("\n");
printf("long dobule : %Le ~ %Le", LDBL_MIN, LDBL_MAX);
return 0;
}
|
cs |
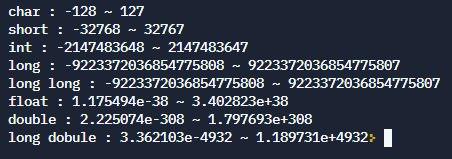
근데 왜 long 결과값이 long long하고 똑같을까.. 알려주실분 구해요
출력타입도 정리해야 하나 했네요..
long 타입의 경우 %d로 하면 결괏값이 안나와서 %ld로 하고, 실수형도.. 모르니까 산넘어산 ㅡㅡ
아무튼 정리해보긴 했는데, 빠진게 있습니다.
정수형의 경우 Signed , Unigned 로 2가지로 나뉘는데, Signed는 위에서 범위를 표시했던
음수와 양수를 둘 다 표현한 것이며,
Unsigned는 양수만 표현 하는 것 입니다. 양수만 표현하니까 범위가 더 넓겠죠?
char 타입 기준으로 -128 ~ 127 범위를 갖는데 Unsigned는 0~255까지 표현이 가능합니다.
넣어야하나 말아야하나 했는데 안넣을려고 합니다.
잘못된 내용이 있다면 댓글 부탁드리겠습니다. (빠른수정 준비완료)
감사합니다;.~